Predicting your BMI from just a photo - a Github safari
For the past few days I've been trawling the internet looking for software. Specifically, software that tries to predict your BMI based on just a foto of your face. During my research I've spotted some weird, exotic and sometimes beautiful creatures, and I wanted to share my findings with you.
Before we begin, let's talk about BMI.
A Body Mass Index is a number that can describes the ratio between your weight and your height. It can offer a basic insight into whether someone is over- or underweight. The Body Mass Index a commonly used metric, even though there has been a lot of pushback to using it. Like many of these scores, it can oversimplify a complex and nuanced situation. What can be concidered a healthy BMI is dependent on a number of factors, such as gender (men have wider faces) or the climate you live in. Although as you'll see in the projects mentioned below, these factore are rarely taken into account properly.

Excerpt from this CDC document about the complexities of using BMI scores.
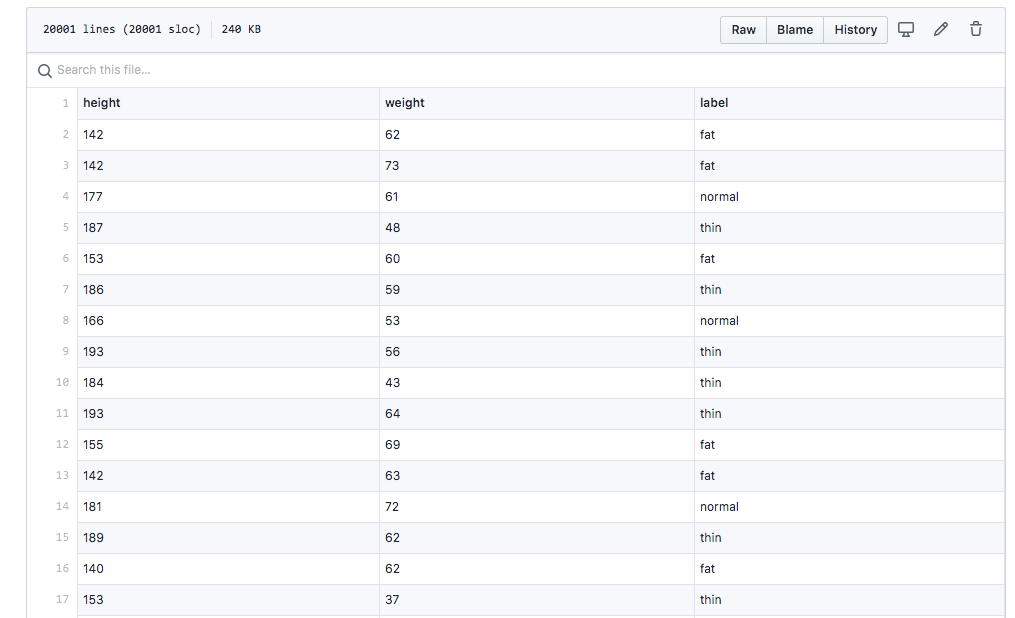
Take for example this data from a Chinese project, which places people in just three categories: thin, normal or fat. It doens't seem to take gender into account, which would lead to women getting a lower BMI score than expected (being seen as "thin men"), while men could get a higher score than expected.
My starting point for these searches is the Github website, where a lot of software projects can be found. Many of them are open source, allowing others to re-use the code. If you engage a commercial service to do BMI analysis for you, there's a good chance their algorithms build upon (academic) work found on Github.
A large number of these BMI prediction projects originate in India and China. Github is one of the last big websites that the Chinese government hasn't blocked or built local alternatives for, so it offers an interesting glimpse into what is concidered 'normal practice' there.

Another example that does not mince words (notice one 'thin' and three 'fat' categories).
Github projects generally have a "readme" section that explains what the project is, so it's the logical place to start. Unfortunately these descriptions are often very minimal, like this one for the project I mentioned earlier:

Sometimes the explanation is more detailed though. If you're lucky the makers offer guidance on how to install the project on your own computer. If you're really lucky it even points to a scientific publication that goes into the thinking behind the algorithm's design.
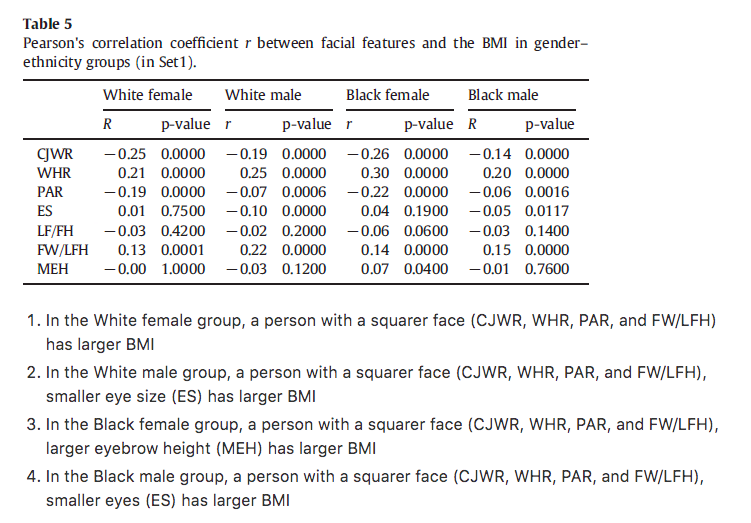
An example from a scientific publication that acknowledges the gendered nature of BMI.
An important question is: how do you predict the BMI from just a photo in the first place?
As Cathy o'Neill explained in her book "Weapons of Math Destruction", the assumption behind these projects is that it's possible to find 'proxy data' that can stand in for the data you actually want in the first place. Since people aren't likely to share information about their weight and length, the 'trick' is to look for other data that may correlate with what you actually want to know. So the question any project has to first answer is: "what is a potential alternative indicator for the thing we actually want to know?".
When it comes to finding a correlation between BMI and faces, I found two common approaches.
The first approach is to measure the dimentions of some facial features which the developers believe accurately correlate with BMI. To make this easier the face is first recuded down to 68 'facial landmarks'. There are a number of generic face detection algorithms that can all extract these 68 points, although in my own work I've noticed some subtle differences. For example, some use less points for the jawline and more for the eyes.

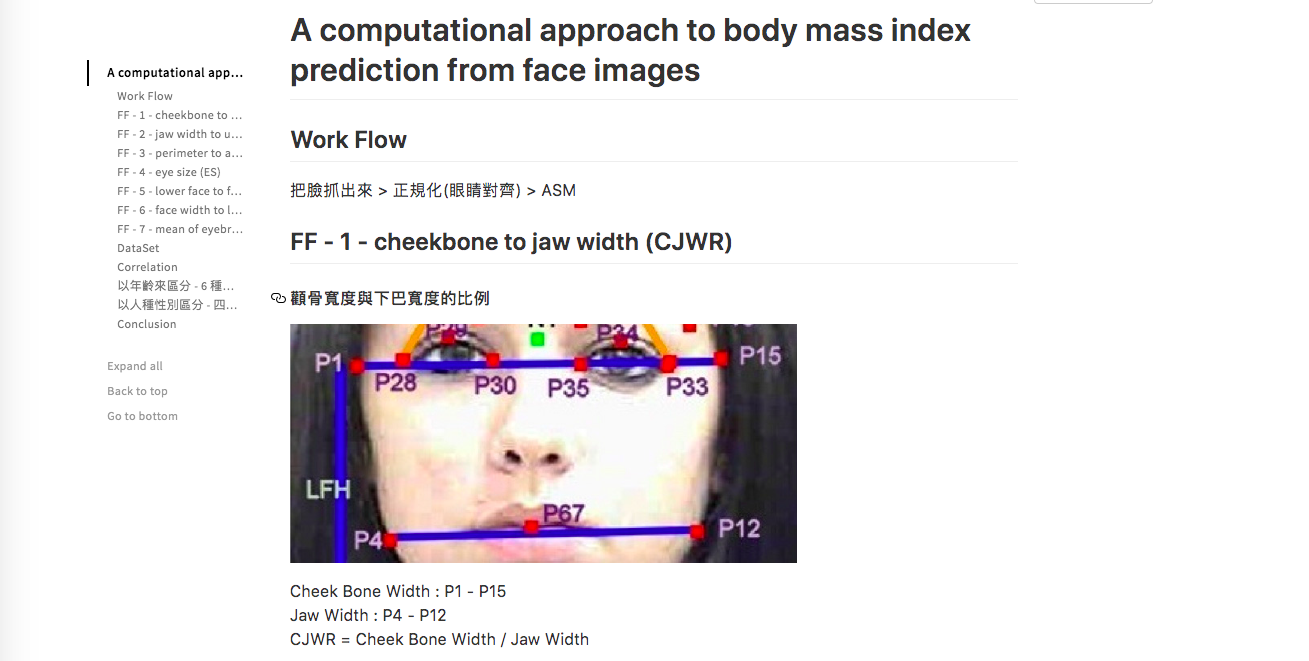
Next, a smaller subset of facial features to actually measure is decided upon. For example, this popular project from China boils it down to seven distinct ratios.
Eyebrows are an interesting indicator here. In the picture below, look at the two yellow lines that intersect on the forehead. The researchers wanted to know the height of the face, but the standard algorithms don't provide "top of the face" as one of the 68 points. So the reseachers had to find a way to 'fake' it. They extrapolated two lines from the corner of your eyes, through to top of your eyebrow. Where they intersect (point "N2") is where they decide the top of your face probably is. Whie it works in the example picture (on the left), it's very unreliable. You could essentially manipulate this algorithm by simply raising your eyebrows, as this would move 'N2' to a higher position (picture on the right). By the algorithm's calculations you would suddenly seem to have a very tall, slender face.
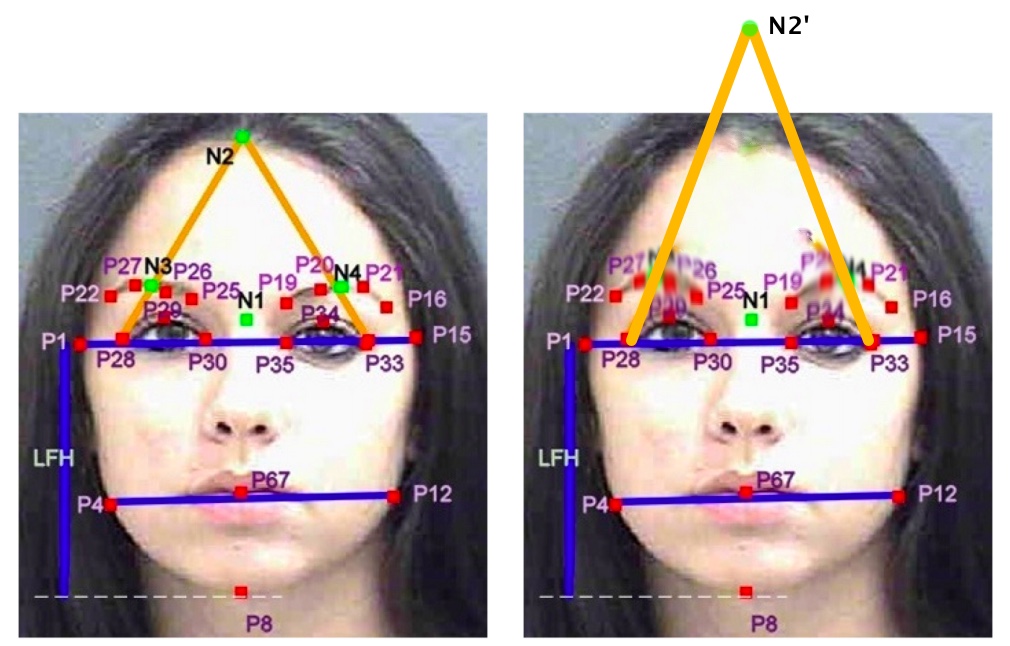
A quick visualisation of how raising your eyebrows could change the analysis. Original on the left.
Here you see pictures a developer created to illustrate what is being measured. Like a form of 'found art', these pictures can be fascinating example of The New Aesthetic.



Later I came accross similar measurement approach in another project, but as you can see it measures similar parts of the face, but limits itself to six.

If you compare it to the previous project, you'll notice for example how both of them measure 'PAR': the surface area of the bottom of the face.
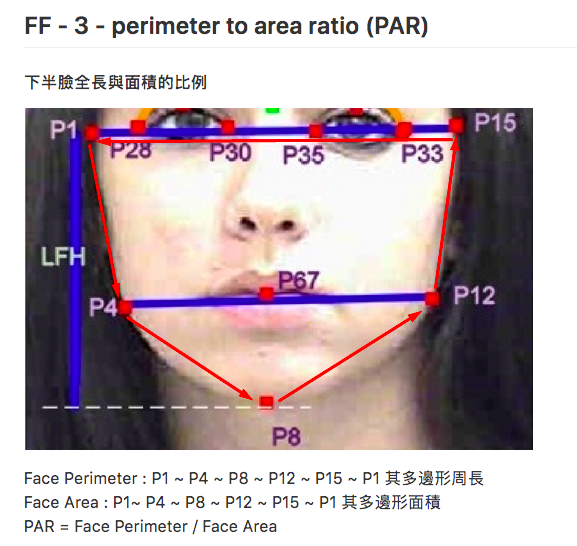
You may wonder: how are these specific aspects decided upon? There is some research by psychologist David Coetzee that seems to be influential here. Oddly, in his own research Coetzee points out that the 'PAR' ratio, which describes the ratio of the the length of your jawline to the surface are of the bottom half of your face, did not correlate with BMI. Yet this factor is implemented in all measurent-based algorithms I came across.

An excerpt from Coetzee's research on the perimeter-to-area ratio (PAR).
A second approach to training BMI prediction algorithms is to skip the part of extracting and measuring specific facial features altogether. Instead, an algorithm is simply fed a lot of pictures of people's faces, where each photo also has a BMI score. After feeding an algorithm thousands of photos, it can start to detect certain patterns in the photos that correlate with a lower or higher BMI score. Essentially, it uses all the pixels of the photo instead of specific facial features. This 'brute force' approach creates algorithms that are even more of a 'black box', since the designers have less control over what the algorithm is actually 'measuring'. For example, if more of the overweight people in the dataset accidentally had the same type of background (or black hair, or more tatoos, or smaller ears, or freckles, etc), it could pick up on that too. In the end you can never guarantee what the algorithm is triggering on. All you can do is show it a photo that it wasn't trained on, one with a a very different type of background, different lighting, and blonde hair, and check if it still makes a valid prediction. Ideally you'd have thousands of photos to train the algorithm, and thousands more (which are sufficiently different) to test it.
In either case, both approaches require a truckload of photos that are all labeled with accurate height and weight measurements. On top of that the dataset should be representative of the population you want to deploy the algorithm in. In other words, the data should not only be 'big', it should also be 'good'.
And that's where it gets tricky.
Ask yourself: where would you get thousands of well-lit, high quality photos with accurate weight and height data?
For Google's research branch in India, the answer is to grab photos from popular community discussion platform Reddit. There you can find communities of people who share updates on their progress to lose weight. These people proudly post pictures of themselves, as well as their before and after weight. These people probably have no idea that Google is systematically downloading their photos to train algorithms, let alone algorithms whose judgements may one day negatively affect them.
![]()
A post in the Progresspics community on Reddit
Google's face-to-BMI project - and its scraping code - can be found on Github.

Part of the code that downloads 'progress pics' from people who are losing weight.
This process of systematically downloading massive amounts of data from websites is called "web scraping".
Similar to Google, this project also scrapes images from Reddit.
Another popular source of photos are American arrest records. They contain exactly what you need: evenly lit mugshots coupled with data about the weight and height of the person.
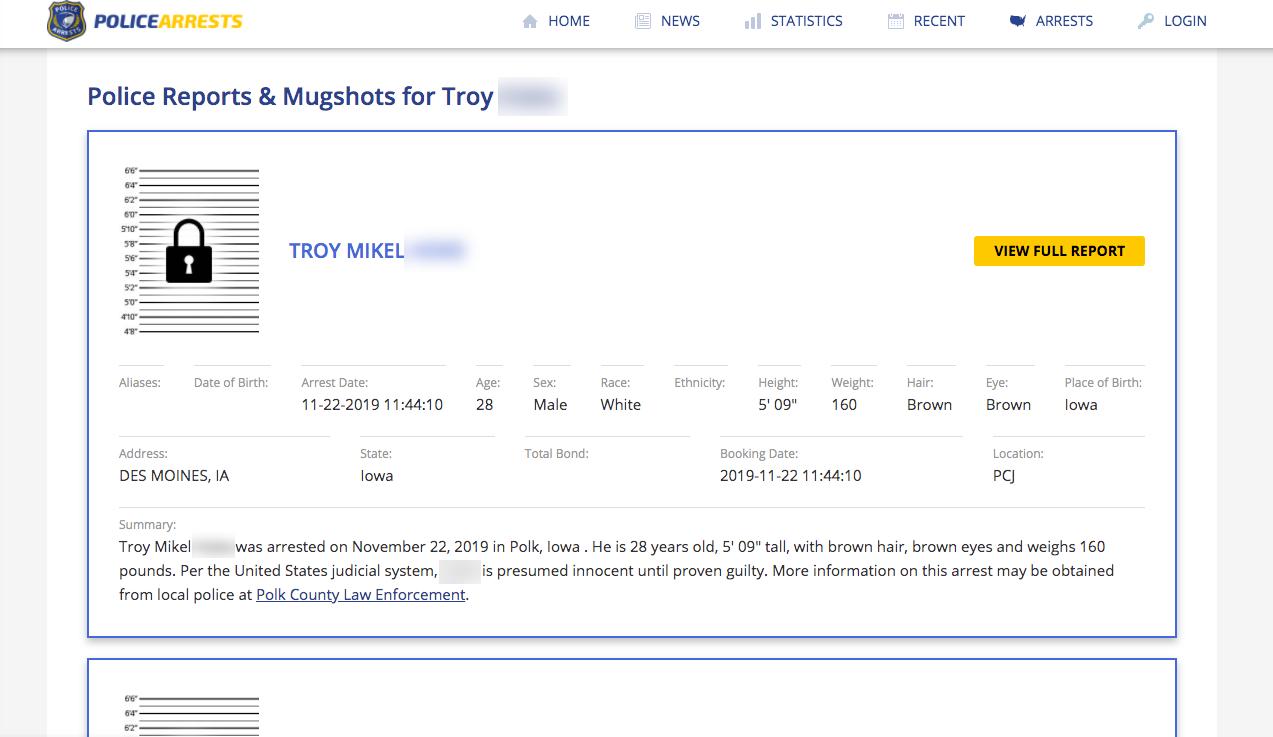
I've blurred the last name in the screenshot above.
 Code that scrapes photos from Iowa arrest records.
Code that scrapes photos from Iowa arrest records.
At one point I was looking at a project's code, and noticed how they called the photos "inmates", and I didn't understand why. Only later did I realise this probably meant they also use to this type of data.
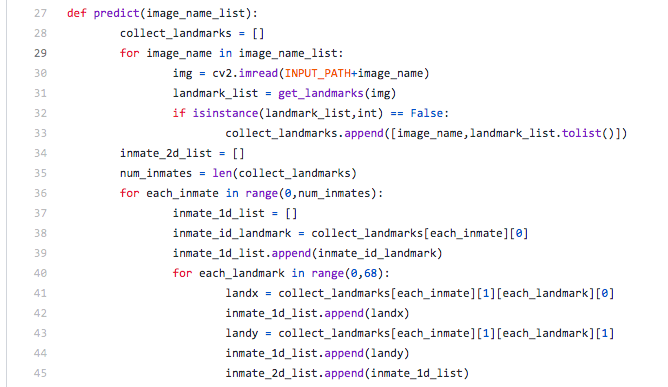
From line 34 and onwards the code mentions going over "inmate" data.

Yet another project (possibly for "AI" insurance company Genlife) that seems to use mugshots.
A third popular source of photos is Hollywood. Photos of actors from the Internet Movie Database are often used to train face recognition projects. In this search I came across a lot of pictures of Indian celebrities. I was surprised to find scientific research (see the example below) that combined these photos with data about celebrities weight and height from sites like www.howtallis.org. Because two sets of data are glued together, the accuracy would be rather low. For example, the moment the photo of a celebrity was taken and when the weight was "deduced" could be far apart.
Actor Christian Bale has gained and lost a lot of weight for some of this roles. His photos offer a lighthearted way of showing what the algorithms can do:

Other websites whose contents were scraped are a waterpolo website, a basketball website, and height-weight-chart.com.

A screenshot of height-weight-chart.com (with blurred faces)
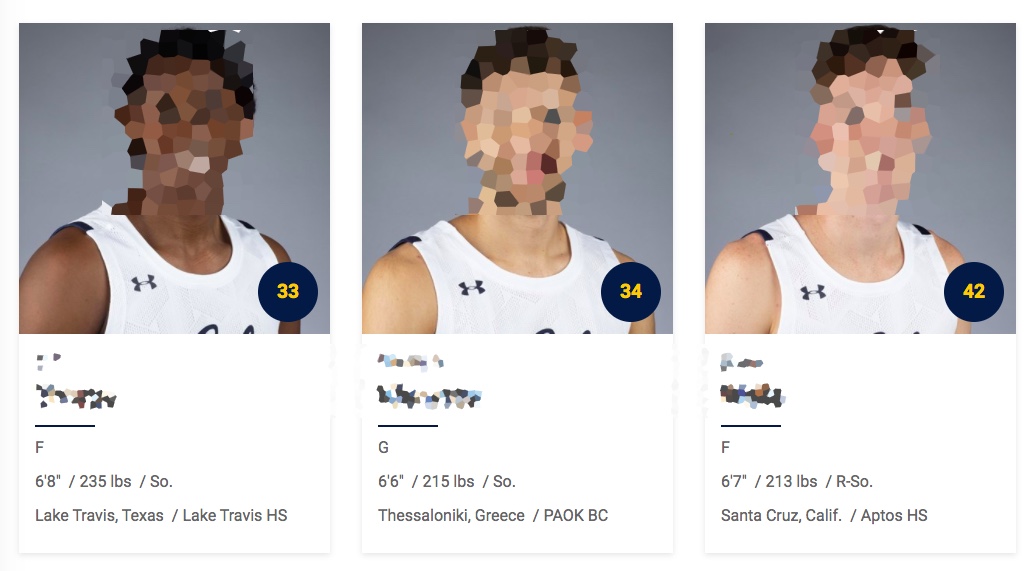
The basketball website that was used as a data source by one of the projects I found
All these sources should raise questions about how representative the training data is for the audience on which it will be unleashed. What kind of prediction will an algorithm trained on western male waterpolo athletes give when it's let loose on black women? Its one of those complexities: athletes tend to have more heavy musclemass, and thus a higher BMI, despite not having much fatty tissue at all. An algorithm trained on male athletes should only really be used on other male athletes.
It can be very hard to figure out what photos are part of a dataset. Creators often cannot or are unwilling to share their training data. They may be protecting privacy or a competitive edge. I suspect in a lot of cases this it's done to hide the poor quality of the dataset, and where the pictures came from.

The size of datasets can also be artificially inflated. A common practise is to take a photo and create some alternate versions of it. A brighter one, a darker one, a slightly rotated one, etc. This makes it good practise to ask how many of the photos are actually of unique people.

What are these algorithms used for?
One of the reasons I wanted to explore these algorithms is that I'm curious about how they are implemented in larger projects. Those too can be found on Github.
One group that is interested in this is the insurance industry. For them predicting your BMI is just the beginning. With it they can make even further rickety predictions about you, such as how long you are likely to live. Some insurers have launched contests to see which team of 'data scientists' could come up with the 'best' algorithm to make health predictions.
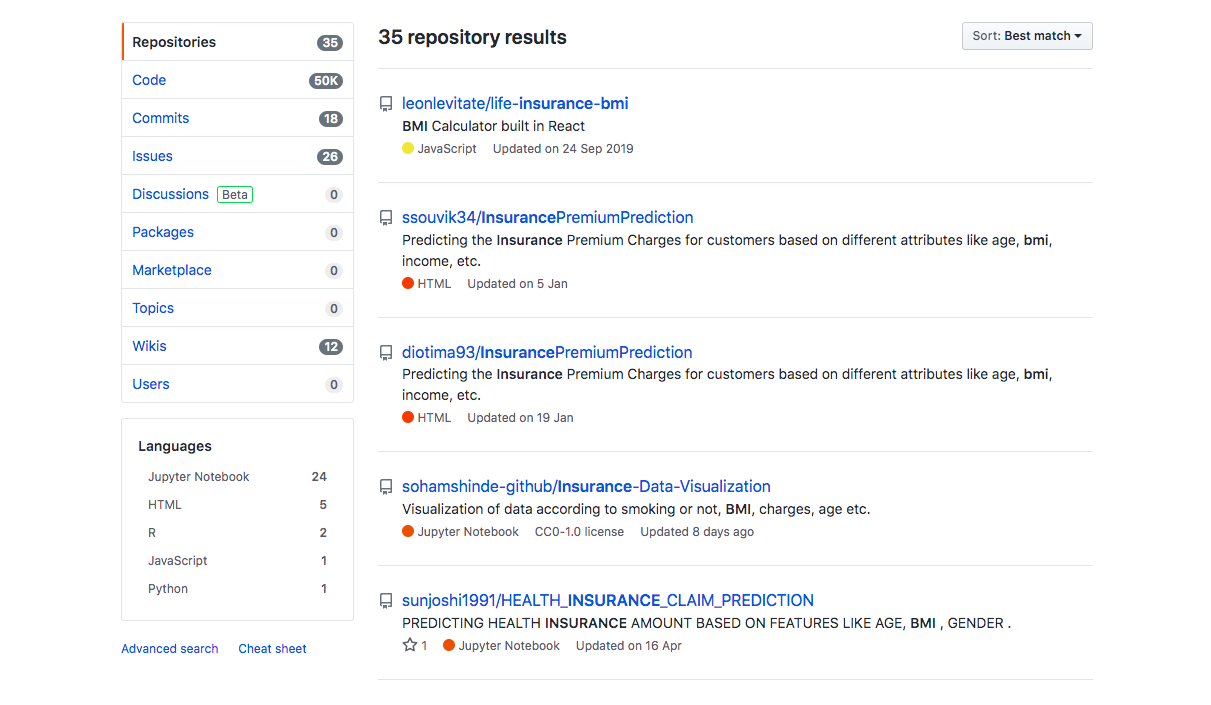
Some insurance and BMI related projects on Github.
I also found one project that tries to predict BMI based on full body photos. This could be used with surveillance camera footage, for example.

Some larger projects are less clear cut. I'm still not sure what this project is about:
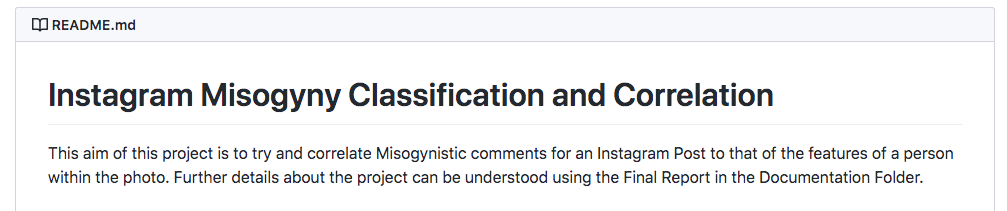
It seems to analyse the text people post on Instragram to pick out mysoginist comments. But then it seems to also analyse the pictures to determine BMI and.. clothing of the people making the mysogenist comments. But.. why?
Data science or data horoscope?
As we come to the end of this safari, I hope I've been able to show how a lot of these creations exhibit questionable design choices, and how they're often trained on whatever data could be scraped together. Some scientists worry that the practices that are concidered normal in "data science" could eventually give actual science a bad name. It's the reason I put the word "data scientist" in brackets nowadays
A lot of the developers do acknowledge the limitations of their work. As I looked through the code of these projects I noticed a lot of small comments where the developers complain about or acknowledge the limitations. For example, they might mention that it greatly matters how the photo is lit, if it's cropped, if it's tilted or it's photographed from the front or a bit off to the side. Or they might point out it won't work as well if you are black or Chinese.
Furthermore, most of these projects bolt the BMI prediction part on top of more generic face detection algorithms, and many of those offer very poor face detection for minorities or certain ethnicities to begin with.
In my opinion these BMI predictions should be taken as seriously as a horoscope prediction.
Some of these projects are used for lighthearted fun, such as apps that predict your life expectancy based on your predicted BMI. But the reality is that these 'educated guesses' are often taken very seriously. For example by insurers and pension funds. There are a wide range of companies that cater to them.

I suspect a lot of end-customers that want to implement these BMI prediction algorithms have inflated expectations. The pitch that "data science" could automate some of their work, and make "more objective" decisions is understandably seductive. Calling these capabilities "artificial intelligence" is part of that seduction. But it's giving these algorithms way too much credit.
Instead of "AI" we should call these creations what they really are: "statistics on steroids".
As a society we've come to understand the limitations of statistics. Once hailed as a revolutionary technology, we now joke about "lies, damn lies, and statistics". Our understanding of machine learning will need to go through a similar cool down period, after which more nuanced visions will prevail.
Awareness is growing at a snails pace though, and I can think of a couple of reasons why. Aside from the blinding hype, one important issue is that questionable algorithms can still make these companies money. An algorithm that is correct 70% of the time can be very profitable. At the same time those 30% bad predictions might have very real consequences - being unfairly denied health insurance for example. Too often these issues are shrugged off as 'temporary glitches' that will surely be fixed as the technology marches on. Or, more cynically, they are labeled as acceptable collateral damage.
That is, if the issues come to light at all. For now, the hidden cost of our data driven world remains mostly hidden, simply because most of us don't realize when we are algorithmically judged in the first place. I suspect it's part of why there's still so little uproar when a "computer says no": we don't know.
But as you can see, the signals are there. On Github.
Part 2 of this research report looks at all the questionable choices I had to make while designing my own BMI prediction algorithm.
If you'd like to go on your own "Github Safari", simply use Github's search function. Type 'face' followed by a trait you're interested in, and see for yourself how deep the rabbit hole goes.
Manuela
May 08, 2021Sla
Ludmila
May 20, 2021Gdhd
Eva
May 20, 2021Hdhdjdjdjdj
Hansnd
Jul 20, 20211646
Huongmo
Jul 22, 2021Đẹp không
Minh
Jul 23, 20213054
Minh
Jul 23, 2021Ụndjdjdj
Thảo
Jul 23, 2021Msks
Quan
Aug 07, 2021Tui được trai k
Quan
Aug 07, 2021Tui được trai k
Khang Lữ
Aug 08, 2021Tui được trai k
Ngọc ánh
Aug 09, 2021Tuii muốn xem bao nhiêu điểm
merve
Aug 10, 2021a
Hương
Aug 12, 2021Tui muốn xem bao nhiêu điểm
Mena
Nov 04, 2021N
Neimy
Nov 24, 2021hsusbsusjxk
Jesús
Feb 26, 2022Hola
Jesús
Feb 26, 2022Hola
Jkgc
Jul 08, 2022Idzditd7dtutdt
Igczxid
Jul 08, 2022Izcid7dutd8td
황서연
Jul 17, 2022Good
Saif
Oct 15, 2022Niente
Anna
Oct 15, 2022Bo
Adolfo
Oct 15, 2022italian boy
Gregorio
Oct 15, 2022Beli sinapsi
Antonella
Oct 15, 2022che voto mi darà la macchina
Antonella
Oct 15, 2022che voto mi darà la macchina
.
Oct 15, 2022.
Oct 16, 2022bho
Alessandro
Oct 16, 2022Ma nn va